on
Action Recognition - Summary of Two Steam CNN paper
About Paper
- Title: Two-Stream Convolutional Networks for Action Recognition in Videos (Two-Stream CNNs)
- Submission date: 9 June 2014
Key Contributions
- Authors proposed a two-stream convolutional network architecture which incorporates spatial and temporal networks.
- Demonstrated that a CNN trained on multi-frame dense optical flow achieves a very good performace despite limited training data.
- They showed that multi-task learning, applied to two different action classification datasets, can be used to increase the amount of training data and improve the performance on the both.
Action recognition in videos
Recognition of human actions in videos is a challenging task as this involves temporal component of videos in addition to the spatial recognition. In this paper, authors aimed at extending deep CNNs to action recognition. Previously this task was addressed by inputing stacked video frames to the CNN. But it was observed that results were very poor compared to the hand-crafted features.
Therefore, the authors investigated a different architecture based on two seperate recognition streams, spatial and temporal, which are then combined by late fusion.

The idea is videos can be decomposed into spatial and temporal components. The spatial part in the individual frame carries information about scenes and objects depicted in the video. The temporal part in the form of motion across the frames conveys the movement of the observer (the camera) and the objects. These two parts are seperately implemented using a deep CNN, softmax scores of which are combined by the late fusion.
Averaging and training a multi-class linear SVM on stacked \(L_{2}\)-normalised softmax scores as features are the two fusion methods considered by the authors.
Spatial Convolutional network is essentially an image classification architecture which can be pre-trained on a large image classification dataset like ImageNet. The temporal convolutional network takes a stack of optical flow displacement fields between several consecutive video frames as input. The brief description of optical flow CNN is given below.
Optical flow CNNs
The optical flow displacement fields explicitly describes the motion between video frames, which makes the action recognition easier, as the network does not need to estimate motion implicitly.

The above set of images explains optical flow in detail:
- (a) and (b) images are the pair of two consecutive video frames with the area around a moving hand outlined with a cyan rectangle.
- (c): The image displays a dense optical flow
- (d): horizontal component \(d^{x}\) of the displacement vector field.
- (e): vertical component \(d^{y}\) of the displacement vector field.
- (d) and (e) highlight the moving hand and bow.
The input to a temporal CNN model contains a multiple flows. The two variations of the optical flow-based input are described below:
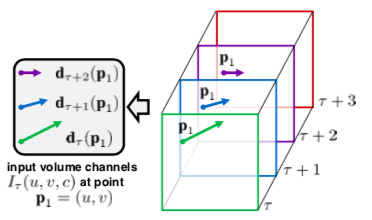
The above figure describes the first variation, optical flow stacking. It can be seen as a set of displacement vector fields \(d_{t}\) between the pairs of consecutive frames \(t\) and \(t + 1\). This method samples the displacement vectors d at the same location (u, v) in multiple frames and are given as input to the temporal CNN model.
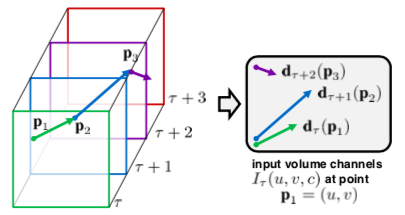
The above figure is the second variation for motion representation. Here the method samples the vectors at the locations (u, v) - \(p_{k}\) along the trajectory and this stack will be given as input to the model.
Experiments
The above architectures were trained and evaluated on the below standard video actions benchmarks
- UCF-101
- 13k videos in total (180 frames/video on average)
- annotated into 101 action classes
- HMDB-51
- 6.8k videos in total
- annotated into 51 action classes
The following are the observations from the results of experiments.
- Spatial CNN solely trained on the UCF-101 dataset leads to over-fitting, therefore authors opted for training the last layer on top of a pre-trained CNN.
- Experiments on temporal CNN resulted that optical flow stacking performs better than trajectory stacking.
- Temporal CNNs significantly outperform the spatial CNNs, which confirms the importance of motion importance for action recognition.
- Multi-task learning performs the best, as it allows the training procedure to exploit all available training data.
- Temporal and spatial recognition streams are complementary, as their fusion significantly improves on both (6% over temporal and 14% over spatial nets).
- SVM-based fusion of softmax scores outperforms fusion by averaging.
Conclusion
The two recognition streams are complementary and the combination deep architecture significantly outperforms and is competitive with the state of the art shallow representations in spite of being trained on relatively small datasets.