on
NLP - Neural Machine Translation by jointly learning to align and translate
About Paper
- Title: Neural Machine Translation by Jointly Learning to Align and Translate (RNNSearch)
- Submission Date: 1 Sep 2014
Key Contributions
- Unlike the traditional statistical machine translation systems (which consists of many small sub-components that are tuned seperately), this paper aims at building a single neural network that can be jointly tuned to maximize the translation performance.
- In this paper, authors conjectured that the use of a single fixed-length encoded representation of source sentence in the basic encoder-decoder is a bottleneck for the performance.
- Therefore, authors extended this basic encoder–decoder model so that decoder automatically (soft-)searches the parts of the source sentence that are relevant to predicting a target word.
Encoder Decoder Models
The models proposed previously for neural machine translation often belong to a family of encoder-decoder models. The encoder architecture encodes a source sentence to a fixed-length vector. From this fixed-length vector, decoder generates a translation to the source sentence.
The potential issue with the above structure is that encoder neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This might make it difficult for the encoder to cope with long sentences, especially those that are longer than the sentences in the training corpus.
In order to address the above issue, authors introduced an extension to the above basic encoder–decoder model which learns to align and translate jointly. Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words. The following sub-section, RNN Encoder-Decoder has the brief description of the proposed model.
RNN Encoder-Decoder
The proposed new architecture (RNNSearch) is illustrated in the below figure.
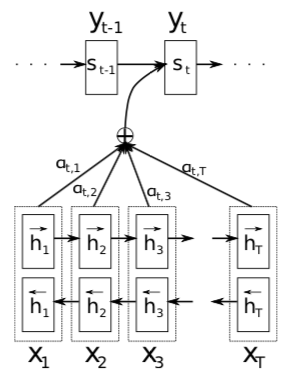
The architecture consists of a bidirectional RNN as an encoder and decoder that imitates searching through a source sentence decoding a translation.
The bidirectional RNN consists of forward and backward RNN’s. The forward RNN reads the input sentence as it is ordered (from \(X_1\) to \(X_T\)) and calculates a sequence of forward hidden states \((\overrightarrow{h_1},..., \overrightarrow{h_T})\). The backward RNN reads the sequence in the reverse order (from \(X_T\) to \(X_1\)), resulting in a sequence of backward hidden states \((\overleftarrow{h_1},..., \overleftarrow{h_T})\). To obtain an annotation for each word \(x_j\), concatenate the forward hidden state \(\overrightarrow{h_j}\) and the backward one \(\overleftarrow{h_j}\) , i.e., \(h_j = \Big[\overrightarrow{h_j}^\top;\overleftarrow{h_j}^\top\Big]\) . In this way, the annotation \(h_j\) contains the summaries of both the preceding words and the following words.
The context vector \(c_i\) is, then, computed as a weighted sum of these annotations \(h_i\) \[c_i = \sum_{j=1}^{T}\alpha_{ij}h_j\]
The weight \(\alpha_{ij}\) of each annotation \(h_j\) is computed by \[\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T}exp(e_{ik})} \] where, \[e_{ij} = a(s_{i-1},h_j)\]
is an alignment model which scores how well the inputs around position j and the output at position i match.
The target word \(y_t\) generation can be defined using conditional probability as \[p(y_i/y_1,…,y_{i-1},X) = g(y_{i-1},s_i,c_i)\], where \(g\) is a nonlinear, potentially multi-layered function that outputs the probability of \(y_i\), and \(s_i\) is an RNN hidden state of the decoder for time \(i\), computed by \[s_i = f(s_{i-1}, y_{i-1}, c_i)\]
The probability \(\alpha_{ij}\) , or its associated energy \(e_{ij}\) , reflects the importance of the annotation \(h_j\) with respect to the previous hidden state \(s_{i−1}\) in deciding the next state \(s_i\) and generating \(y_i\). Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to
Experiments
Dataset used for experiments is WMT’14 contains the following English-French parallel corpora. Authors trained two types of models. The first one is an RNN Encoder–Decoder, and the other is the RNNsearch. The encoder and decoder of the RNNencdec have 1000 hidden units each. The encoder of the RNNSeach consists of forward and backward recurrent neural networks (RNN) each having 1000 hidden units. Its decoder has 1000 hidden units. We train each model twice: first with the sentences of length up to 30 words (RNNencdec-30, RNNsearch-30) and then with the sentences of length up to 50 word (RNNencdec-50, RNNsearch-50). The observations from the experiments are:
- In both the lengths, the proposed RNNsearch outperforms the conventional RNNencdec.
- The performance of the RNNsearch is as high as that of the conventional phrase-based translation system
- The performance of RNNencdec dramatically drops as the length of the sentences increases
- The RNNsearch architecture enables far more reliable translation of long sentences than the standard RNNencdec model.
Conclusion
The most important distinguishing feature of the RNNSearch from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. Therefore, this allowed the model to cope better with long sentences.