on
Summary of BERT Paper
About Paper
- Title: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Bert)
- Submission Date: 11 oct 2018
Key Contributions
- Introduced a new language representation model BERT (Bidirectional Encoder Representations from Transformers) which improves fine-tuning based approaches.
- Argued that major limitation of the previous standard language models are unidirectional, which limits the choice of architectures that can be used for pre-training.
- Introduced “mask language model” (MLM) objective, which helped in pre-training deep bidirectional transformer.
- Also introduced a ‘next sentence prediction’ task that jointly pre-trains text-pair representations
- Showed that pre-trained representations eliminate the needs of many heavily engineered task-specific architectures.
Achievements
- Obtains new state-of-the-art results on eleven natural language processing tasks,
- Pushed the GLUE benchmark to 80.4% (7.6% absolute improvement).
- MultiNLI accuracy to 86.7% (5.6% absolute improvement)
- SQuAD v1.1 question answering Test F1 to 93.2 (1.5 absolute improvement)
Pre-training to down stream tasks
There were two existing stratagies for applying pre-trained language representations to down stream tasks.
- feature-based approach
- fine-tuning approach
Feature-based approach
Feature-based stratagies uses task specific architectures that include pre-trained representations as additional features
Fine-tuning approach
Fine-tuning approach introduces minimal task-specific parameters, and is trained on the down-stream tasks by simply fine-tuning the pre-trained parameters. OpenAI GPT follows the same procedure and achieved previously state-of-the-art results.
Fine-tuning using BERT
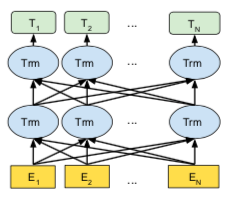
BERT addresses the previously mentioned unidirectional constraints by proposing a new pre-training objective: the “masked language model”(MLM). The masked language model randomly masks some of the tokens from input. The objective is to predict the vocabulary id of masked word based on the context. The MLM model objective allows the representaiton to fuse the left and right context (as shown in below figure), which helped in pre-training a deep bidirectional transformer.
The input representaiton to the bert is a single token sequence. For a given token, it’s input representation is constructed by summing the corresponding token, segment and position embeddings as shown in below.
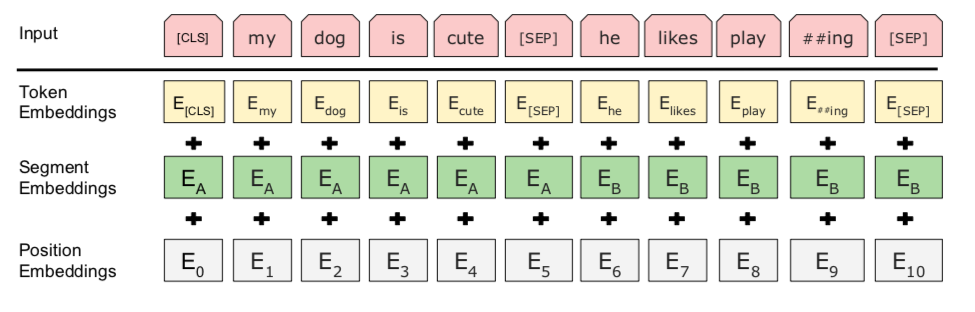
The first token of the sequence is always the special classification embedding ([CLS]). The final hidden state (i.e, the output of the transformer) corresponding to this token is used as aggregate sequence representation for classification tasks.
Sentence pairs are packed together into a single sequence. The structure of the sentence fusion is as follow: seperate the pairs by a special token ([SEP]). Then add a learned sentence A embedding to every token of first sentence and a sentence B embedding to every token of the second sentence.
Many important down-stream tasks such as Question answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between pair of sentences. In order to train a model that understands the sentence relationship, authors pre-trained a binarized next sentence prediction task.
Comprasions between BERT and OpenAI GPT
The core argument of the paper is that two novel pretraining tasks (with BERT and OpenAI GPT) account for majority of the emprical improvements. But the noted differences between these two are mentioned below.
| GPT | BERT |
|---|---|
| GPT is trained on the BooksCorpus (800M words) | BERT is trained on the BookCorpus (800M words) and Wikipedia (2,500 M words) |
| GPT uses a sentence seperator ([SEP]) and classifier token ([CLS]) which are only introduced at fine-tuning time | BERT learns [SEP], [CLS] and sentence A/B embeddings during pre-training |
| GPT was trained on 1M steps with a batch size of 32,000 words | BERT was trained on 1M steps with a batch size of 128,000 words |
| GPT used the same learning rate of 5e-5 for all fine-tuning experiments | BERT chooses a task-specific fine-tuning learning rate which performs the best on the development set |
Observations
- MLM does converge marginally slower than a left-to-right model (which predicts every token), but the empirical improvements of the MLM model far outweigh the increased training cost.
- \(BERT_{BASE}\) and \(BERT_{LARGE}\) differs in network architecture size. \(BERT_{BASE}\) and OpenAI GPT are nearly identical in model architecture outside of the attention masking.
- \(BERT_{BASE}\) and \(BERT_{LARGE}\) outperform all existing systems on GLUE tasks by a substantial margin, obtaining 4.4% and 6.7% respective average accuracy improvement over the state-of-the-art
- \(BERT_{LARGE}\) significantly outperforms \(BERT_{BASE}\) across all tasks, even those with very little training data
- BERT outperforms the top leaderboard system of SQuAD by +1.5 F1 in ensembling and +1.3 F1 as a single system
- BERT outperformed Named Entity Recognition Base model. It also outperformed in SWAG (Situations With Adversarial Generations) by 27.1% from authors baseline.