on
How to Scrape Web using Python, Selenium and Beautiful Soup
In this tutorial, we will learn how to scrap web using selenium and beautiful soup. I am going to use these tools to collect recipes from a food website and store them in a structured format in a database. The two tasks involved in collecting the recipes are:
- Get all the recipe urls from the website using selenium
- Convert the html information of a recipe webpage into a structed json using beautiful soup.
For our task, I picked the NDTV food as a source for extracting recipes.
Selenium
Selenim Webdriver automates web browsers. The important use case of it is for autmating web applications for the testing purposes. It can also be used for web scraping. In our case, I used it for extracting all the urls corresponding to the recipes.
Installation
I used selenium python bindings for using selenium web dirver. Through this python API, we can access all the functionalities of selenium web dirvers like Firefox, IE, Chrome, etc. We can use the following command for installing the selenium python API.
$ pip install selenium
Selenium python API requires a web driver to interface with your choosen browser. The corresponding web drivers can be downloaded from the following links. And also make sure it is in your PATH, e.g. /usr/bin or /usr/local/bin. For more information regarding installation, please refer to the link.
| Web browser | Web driver link |
|---|---|
| Chrome | chromedriver |
| Firefox | geckodriver |
| Safari | safaridriver |
I used chromedriver to automate the google chrome web browser. The following block of code opens the website in seperate window.
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException, \
WebDriverException
driver = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver')
driver.get("https://food.ndtv.com/recipes")
Traversing the Sitemap of website
The website that we want to scrape looks like this:
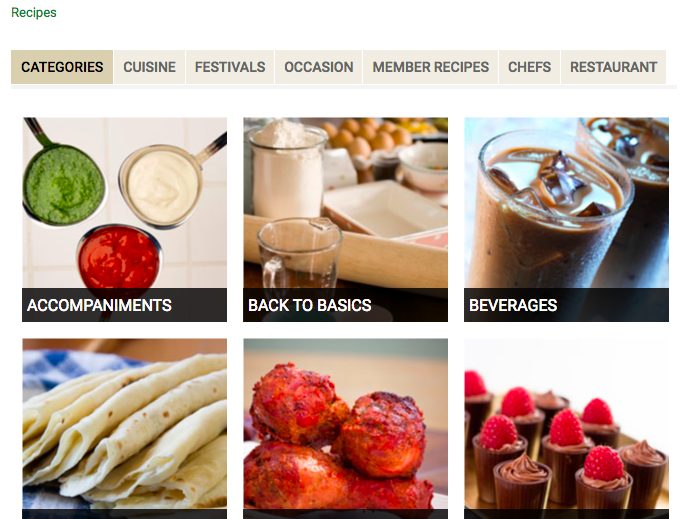
We need to collect all the group of the recipes like categories, cusine, festivals, occasion, member recipes, chefs, restaurant as shown in the above image. To do this, we will select the tab element and extract the text in it.
We can find the id of the the tab and its attributes by inspect the source.
In our case, id is insidetab. We can extract the tab contents and their hyper links using the following lines.
def get_link_by_text(text):
"""Find link in the page with given text"""
element = driver.find_element_by_link_text(text.strip())
return element.get_attribute("href")
def get_list_by_class_name(class_name="main_image "):
"""Get list of text in all element by class_name"""
element_list = []
try:
all_elements = driver.find_elements_by_class_name(class_name)
element_list = [x.text for x in all_elements if len(x.text) > 0]
except (NoSuchElementException, WebDriverException) as e:
print(e)
return element_list
category_links = {x: get_link_by_text(x)
for x in get_list_by_class_name('recipe-tab-heading')}
We need to follow each of these collected links and construct a link hierachy for the second level.
sub_category_links = {}
for category, url in category_links.items():
driver.get(url) # open url in chrome
sub_category_list = get_list_by_class_name("main_image ")
sub_category_links[category] = {x: get_link_by_text(x)
for x in sub_category_list}
When you load the leaf of the above sub_category_links dictionary, you will encounter the following pages with ‘Show More’ button as shown in the below image. Selenium shines at tasks like this where we can actually click the button using element.click() method.
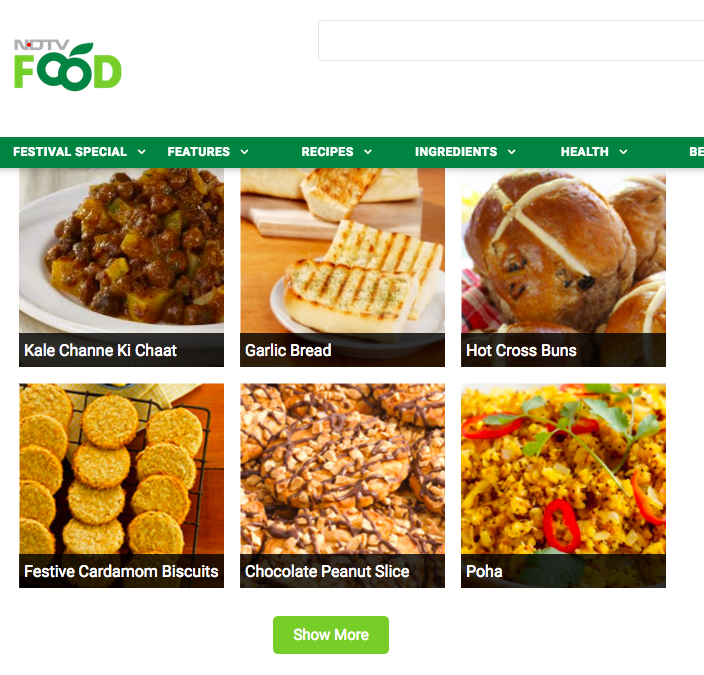
For the click automation, we will use the below block of code.
import time
def keep_clicking_show_more():
"""Loop till show_more doesn't have anything to load."""
while True:
try:
driver.find_element_by_link_text('Show More').click()
# Wait till the container of the recipes gets loaded
# after load more is clicked.
time.sleep(5)
recipe_container = driver.find_element_by_id("recipeListing")
if 'No Record Found' in recipe_container.text:
break
except (NoSuchElementException, WebDriverException) as e:
break
Now let’s get all the recipes in NDTV!
all_recipe_links = {}
for category, urls in sub_category_links.items():
if category == 'CHEFS':
# we want to ignore chefs.
continue
elif category == 'MEMBER RECIPES':
# there's no additional tree traversal for member recipes
all_recipe_links[category] = {
'dummy_sub_category': urls
}
else:
all_recipe_links[category] = {}
for sub_category, url in urls.items():
driver.get(url)
keep_clicking_show_more()
all_recipe_links[category][sub_category] = {
x: get_link_by_text(x)
for x in get_list_by_class_name("main_image ")
}
Beautiful Soup
Now that we extracted all the recipe URLs, the next task is to open these URLs and parse HTML to extract relevant information. We will use Requests python library to open the urls and excellent Beautiful Soup library to parse the opened html.
from bs4 import BeautifulSoup
import requests
url = 'https://food.ndtv.com/recipe-chawal-ki-kheer-951891'
html_doc = requests.get(url).content
soup = BeautifulSoup(html_doc, 'html.parser')
Here’s how an example recipe page looks like:
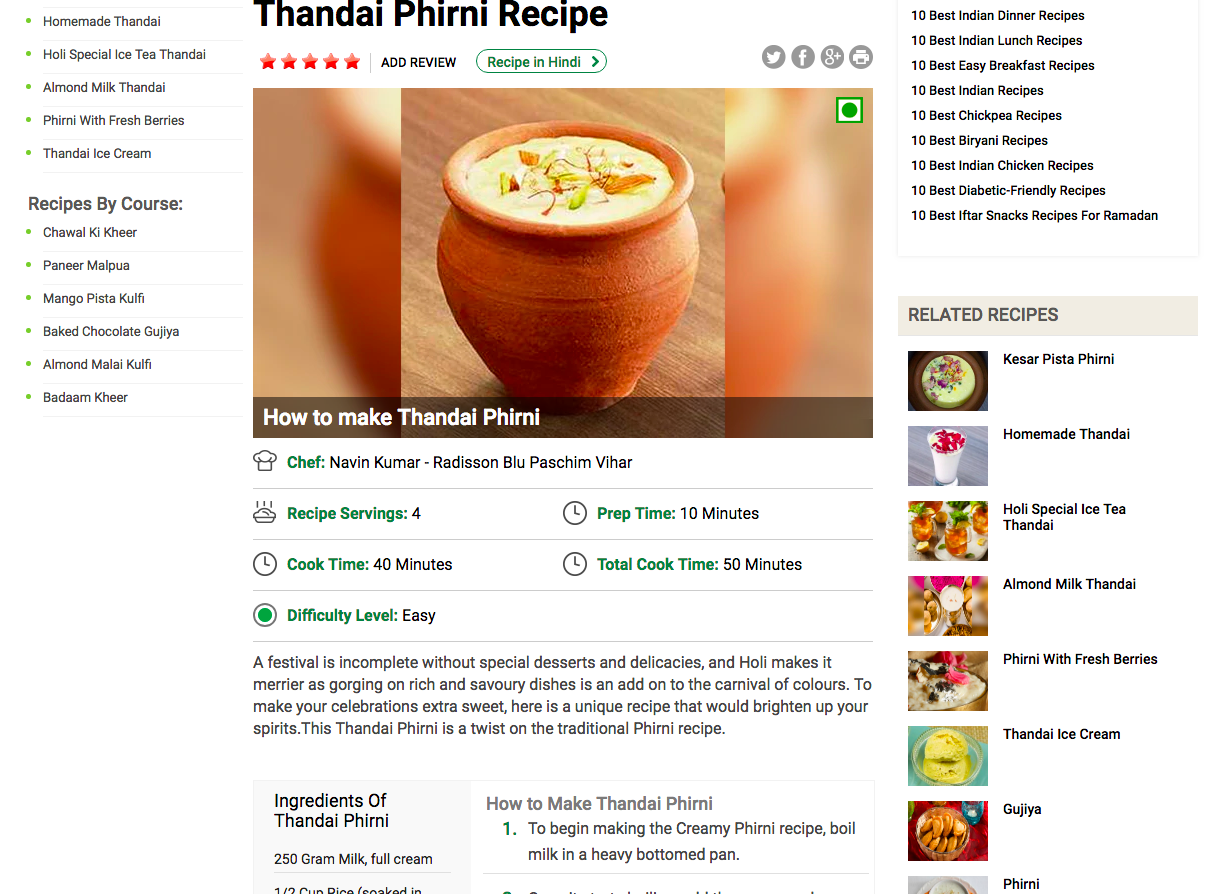
soup is the root of the parsed tree of our html page which will allow us to navigate and search elements in the tree. Let’s get the div containing the recipe and restrict our further search to this subtree.
Inspect the source page and get the class name for recipe container. In our case the recipe container class name is recp-det-cont.
recipe_container = soup.find("div", {"class": "recp-det-cont"})
Let’s start by extracting the name of the dish. get_text() extracts all the text inside the subtree.
# name was in h1 html tag inside recipe container div
name = recipe_container.find('h1').get_text().strip()
Now let’s extract the source of the image of the dish. Inspect element reveals that img wrapped in picture inside a div of class art_imgwrap.
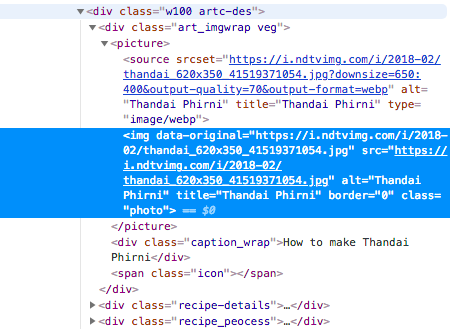
BeautifulSoup allows us to navigate the tree as desired.
image = recipe_container.find(
'div', {'class': 'art_imgwrap'}).picture.img['src']
Finally, ingredients and instructions are li elements contained in div of classes ingredients and method respectively. While find gets first element matching the query, find_all returns list of all matched elements.
# ingredients
recipe_ingredients = recipe_container.find('div', {"class": "ingredients"})
ingredients = [x.get_text().strip()
for x in recipe_ingredients.find_all('li')]
# instructions
recipe_method = recipe_container.find('div', {"class": "method"})
instructions = [x.get_text().strip()
for x in recipe_method.find_all('li')]
Overall, this project allowed me to extract 2031 recipes each with json which looks like this:
{
"title": "Thandai Phirni Recipe",
"difficulty": "Easy",
"prep_time": "10 Minutes",
"cook_time": "40 Minutes",
"servings": "4",
"image_url": "https://i.ndtvimg.com/i/2018-02/thandai_620x350_41519371054.jpg",
"video_url": null,
"source_url": "https://food.ndtv.com/recipe-thandai-phirni-952064",
"source": "NDTV Food",
"ingredients": [
"250 Gram Milk, full cream",
"1/2 Cup Rice (soaked in water for at least 3 hours)",
"2 Cardamoms (crushed,pods/seeds)",
"15-20 strands Saffron (soaked in 2 tbsp milk)",
"3 Tbsp Thandai masala powder",
"1 Cup Sugar (adjustable)",
"2 Tbsp Almonds & Pista, sliced"
],
"instructions": [
"To begin making the Creamy Phirni recipe, boil milk in a heavy bottomed pan.",
"Once it starts boiling, add the green cardamom into the milk.",
"In the mean time, take rice and grind them coarsely in a grinder by adding a little water.",
"Add sugar in the boiling milk, thandai, kesar milk and then add rice into it. Stir it for at-least 20 minutes or till it gets thick.",
"When it starts getting thick, switch off the stove and let it cool properly.",
"Pour it in kullads (earthen pots) and put it in fridge for 2 to 3 hours. Now take it out, garnish it with sliced nuts and serve it chilled.",
"Serve Creamy Thadai Phirni as a dessert after your scrumptious meal or make it during holi to celebrate the festival."
]
}