on
NLP - Summary of Sequence to Sequence with Neural Networks
About Paper
- Title: Sequence to Sequence Learning with Neural Networks (seq2seq)
- Submission Date: 10 Sep 2014
Key Contributions
- In this paper, authors showed a straightforward application of the Long Short-Term Memory (LSTM) architecture which can solve general sequence to sequence problems.
- The novelity of the introduced architecture is that the LSTM reads the input sequence in reverse order, because doing so introduces many short term dependencies in the data that make the optimization problem much easier.
Achievements
- The main result of the paper is that on an English to French translation task from the WMT-14 dataset, the translations produced by the LSTM achieves a BLEU score of 34.8 on the entire test set.
- Additionally, the LSTM did not have difficulty on long sentences.
- When authors used the LSTM to rerank the 1000 hypotheses produced by the phrase-based statistical machine translation(SMT) system, its BLEU score increases to 36.5, which is close to the previous state of the art.
- The LSTM also learned sensible phrase and sentence representations that are sensitive to word order and are relatively invariant to the active and the passive voice
Sequence to Sequence Learning
- In Sequence to Sequence learning, the length of inputs and outputs are not known a-priori.
- Examples of sequential learning are:
- Speech recognition
- Machine translation
- Examples of sequential learning are:
- Despite the DNN flexibility and power, DNNs can only be applied to problems whose inputs and targets are encoded with vectors of fixed dimensionality.
- The above is a significant limitation for sequence to sequence learning.
The Model
The Recurrent Neural Network (RNN) is a natural generalization of feedforward neural networks to sequences. However it would be difficult to train the RNNs due to the resulting long term dependencies. The Long Short-Term Memory (LSTM) is known to learn problems with long range temporal dependencies, so an LSTM is used in this paper.
The overall setting of the architecture is explained in the following figure.
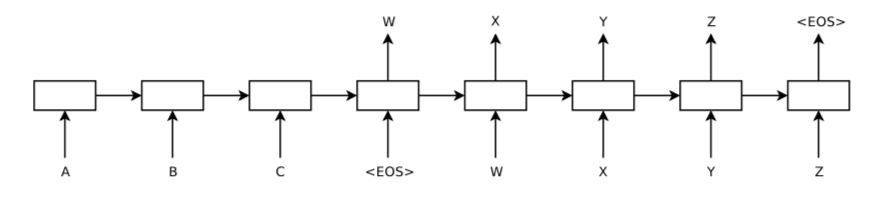
Every sentence ends with a special end-of-sentence symbol
The architecture used in the paper uses two different LSTMs and works as follows.
- One LSTM takes input sequence and converts it to the fixed sized vector.
- Another LSTM converts the fixed vector to the output sequence.
- Using two LSTMs increases the number of model parameters at negligible computational cost and makes it natural to train the LSTM on the multiple language pairs.
- Authors chose a LSTM with four layers as the deep LSTMs significantly outperforms shallow LSTMs
- Reverse the order of the sentences and train the model.
- Instead of mapping the sentence a, b, c to the sentence \(\alpha\), \(\beta\), \(\gamma\), the LSTM is asked to map c, b, a to \(\alpha\), \(\beta\), \(\gamma\), where \(\alpha\), \(\beta\), \(\gamma\) is the translation of a, b, c.
- This way, a is in close proximity to \(\alpha\), b is fairly close to \(\beta\), and so on, a fact that makes it easy for SGD to “establish communication” between the input and the output.
Experiments
The dataset used for experiments is WMT’14 English to French dataset. The authors trained the models on a subset of 12M sentences consisting of 348M French words and and 304M English words.
As typical neural language models depend on a vector representation for each word, authors used a fixed vocabulary for both languages. Authors used 160K of the most frequent words for the source language and 80K of the most frequent words for the target language. Every out of vocabulary word was replaced with a special “UNK” token.
The observations of the experiments are described below:
- Even though LSTM is capable of solving problems with long term dependencies, authors discovered that the LSTM learns much better when the source sentences are reversed (the target sentences are not reversed). By doing so, the LSTM’s test BLEU scores of its decoded translations increased from 25.9 to 30.6.
- Although LSTMs tend to not suffer from the vanishing gradient problem, they can have exploding gradients. Thus authors enforced a hard constraint on the norm of the gradient by scaling it when its norm exceeded a threshold.
- Different sentences have different lengths. Most sentences are short (e.g., length 20-30) but some sentences are long (e.g., length > 100), so a minibatch of 128 randomly chosen training sentences will have many short sentences and few long sentences, and as a result, much of the computation in the minibatch is wasted. To address this problem, authors made sure that all sentences within a minibatch were roughly of the same length, which a 2x speedup.
- The best results are obtained with an ensemble of 5 deep LSTMs using a left to right beam-search encoder that differ in their random initializations and in the random order of minibatches.
- Finally, the LSTM is used to rescore the publicly available 1000-best lists of the SMT baseline on the same task. By doing so, BLEU score of 36.5 was obtained, which improves the baseline by 3.2 BLEU points and is close to the previous state-of-the-art (37 BLEU).
Conclusion
In this paper, authors showed that a large deep LSTM with a limited vocabulary can outperform a standard SMT-based system whose vocabulary is unlimited on a large-scale MT task.