on
NLP - Attention Is All You Need
About Paper
- Title: Attention Is All You Need (Transformer)
- Submission Date: 12 jun 2017
Key Contributions
- Proposed a new simple network architecture, the Transformer, based solely on attention mechanisms, removing convolutions and recurrences entirely.
- Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
- Showed that the transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
Sequence transduction models
The dominant sequence transduction models such as machine translation and language modeling are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The inherent sequential nature observed while modeling recurrent neural networks on training examples precludes parallelization, which becomes critical at longer sequence lengths.
Therefore in this paper, authors proposed the transformer, a model architecture which does not use recurrence and instead rely solely on an attention mechanism to draw global dependencies between input and output sequences. This model also allows for more parallelization.
The transform architecture
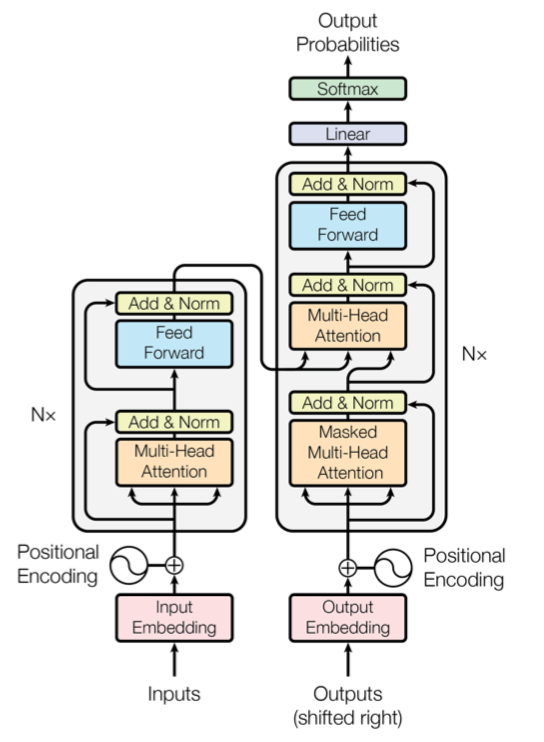
As previously mentioned, the most competitive sequential transduction models follow encoder–decoder architecture. The encoder maps an input sequence of symbol representations \((x_1,....,x_n)\) to a sequence of continuous representations z\(= (z_1,....,z_n)\). Given z, the decoder then generates an output sequence \((y_1,....,y_n)\) of symbols one element at a time. The transformer follows this overall architecture using self-attention and point-wise fully connected layers for both encoder and decoder, shown in left and right side of the below figure respectively.
Encoder
The encoder composes of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism over the input, and the second is the point-wise fully connected feed-forward network. Then residual connection is employed around each of the two sub-layers followed by layer normalization.
Decoder
The decoder is also composed of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder the residual connections are employed around each of the sub-layer in the decoder stack.
Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and outputs are all vectors. The output is computed a weighted sum of the values, where the weight assigned to each is computed by a compatibility function of the query with the corresponding key. The attention models that are used in the transformer are described below.
Scaled Dot-Product Attention
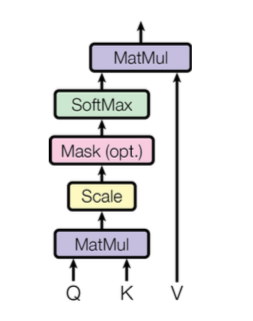
The above particular attention model called as “Scaled Dot-Product Attention”. The input consists of queries, keys and values. We compute the dot products of the query with all keys, divide each by a scaling factor, and apply a softmax function to obtain the weights on the values.
Multi-Head Attention
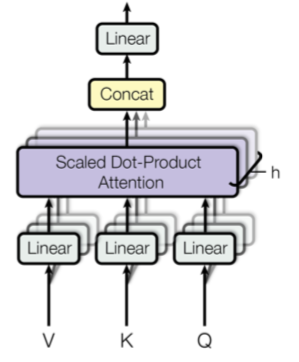
Instead of performing single attention function, in this model queries, keys and values are linearly projected. On each of these h projected versions of queries, keys and values, perform the attention function in parallel yeilding h output values. These are concatenated and once again projected linearly, resulting in the final values.
From above, we can understand that a self-attention layer connects all positions with a constant number of sequentially executed operations, where as a recurrent layer requires \(O(n)\) sequential operations, where n is the sequence length.
Applications of Attention in the model
The transformer uses multi-head attention in three different ways
- In encoder-decoder attention layers, the queries come from the previous decoder layer, and the keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence.
- The encoder contains self-attention layers. In a self-attention layer all the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder.
- The self-attention layers in the decoder allow each position in the decoder to attend to all the positions in the decoder up to and including that position.
Observations
The transformer is experimented on two machine translation tasks i.e., WMT 2014 English-to-German translation task and WMT 2014 English-to-French translation task. The following results are observed.
- Experiments on two machine translation tasks show that these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
- The model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU.
- On the WMT 2014 English-to-French translation task, the transformer model achieves state-of-the-art BLEU score of 41.8.
The transformer also experimented on the task of english constituency parsing to check the generalizability. For this, authors trained a 4-layer transformer on the Wall Street Journal(WSJ) portion of the Penn Treebank, about 40K training sentences. Even when training only on the WSJ training set of 40K sentences, the transformer outforms the BerkelyParser corpora.