on
Summary of Multi-Paragraph Reading Comprehension Paper
About Paper
- Title: Simple and Effective Multi-Paragraph Reading Comprehension (Multi-Paragraph reading)
- Submission Date: 29 oct 2017
Key Contributions
- This paper discusses the problem of adapting the neural paragraph-level question answering models to the case where entire documents are given as input.
- The proposed model samples multiple paragraphs from the relevant documents during training and use a shared normalization training objective that encourages the model to produce globally correct output.
- Then combining the above model with the state-of-the-art pipeline for training on document QA data gave an improvement than the previous best system.
Introduction
The recent success of neural models at answering questions given a related paragraph suggests neural models have the potential to automatically extract the answers from the given documents. Training and testing these models on document level input is extremely computational process, so typically this requires adapting a paragraph level model to process document level input.
Two basic approaches for the task
- Pipelined approaches select a single paragraph from the input documents, which then passed to the paragraph model to extract an answer.
- Confidence based methods apply the model to multiple paragraphs and returns the answer with the highest confidence.
Pipelined Method
- This work proposes an approach to train pipelined question answering systems, where a paragraph is selected using a TF-IDF heuristic and passed to a paragraph level Question Answering (QA) model.
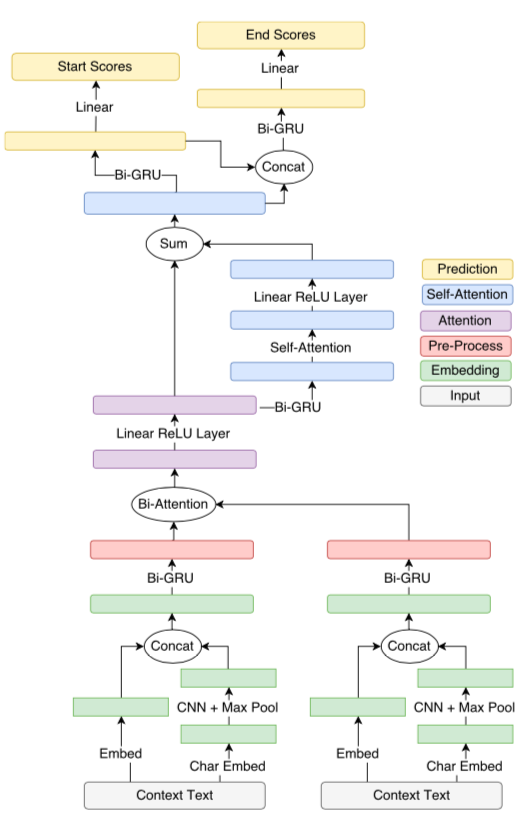
The above paragrah level model uses the following layers and are stated in the right side of the above figure with coloring.
Embedding:
The character-level and word-level embeddings are then concatenated and passed to the next layer. This model do not update the word embeddings during training
Pre-process:
A shared bi-directional GRU (Bi-GRU) is used to map the question and passage embeddings to context-aware embeddings
Attention:
The bi-directional attention mechanism is used to build a query-aware context representation.
Self-attention:
The input of the above is passed through another bi-directional GRU. Then we apply the same attention as above between the passage and itself.
Prediction:
In the last layer of the model, the model computes answer start scores and answer end scores for each token.
- The softmax operation is applied to start and end scores (from the prediction layer) to produce start and end probabilities.
- As our training data contains only the answer text, not the answer spans. To handle this type of noise, we use a summed objective function which optimizes the sum of the probabilities of all answer spans and this function marginalizes the model’s output over all the locations the answer text occurs.
Confidence Method
The authors adapted this model to the multi-paragraph setting by using the un-normalized and un-exponentiated score given to each span as a measure of the model’s confidence. Selecting the answer span based on the highest confidence where confidence measured as sum of the start score and end score results as below.

The two key reasons why model’s confidence scores might not be well caliberated are:
- The pre-softmax scores for all spans can be arbitrarily increased or decreased by a constant value without changing the resulting softmax probability distribution. As a result, nothing prevents models from producing scores that are arbitrarily all larger or all smaller for one paragraph than another.
- If the model only sees paragraphs that contain answers, it might become too confident in heuristics or patterns that are only effective when it is known a priori that an answer exists
Taking above disadvantages authors experimented with four approaches for training models. In all four approaches, authors sample paragraphs that do not contain an answer as additional training points
Shared-Normalization
In this model, all paragraphs are processed independently but a modified objective function is used where the normalization factor in the softmax operation is shared between all the paragraphs from the same context. The key idea is that this will force the model to produce scores that are comparable between paragraphs
Merge
Authors experimented with concatenating all paragraphs sampled from the same context together during training. Here motive is to test whether showing more text will improve performance or not.
No-Answer option
Experimented another method which allows the model to select a special “no-answer” option for each paragraph.
Sigmoid
Also considered training the models with sigmoid - cross entropy loss as an objective function. Since the scores are computed independently of one another, they will be comparable between different paragraphs.
Experiments
- Evaluated the proposed approach on three datasets.
- TriviaQA unfiltered
- TriviaQA web: derived from TriviaQA unfiltered by treating each question-document pair as an individual training point and the correspoding document contains the question answer.
- SQuAD
- For SQuAD and TriviaQA web, authors took the top four paragraphs ranked by TF-IDF score for each question-document pair.
- For TriviaQA unfiltered, a distict paragraph selection method which uses TF-IDF score selects top 16 paragraphs for each question.
- On TriviaQA web dataset, the no-answer option training approach lead to a significant improvement, and the shared-norm and merge approach are even better. On the verified set, the shared-norm approach is solidly ahead of the other options. This suggests the shared-norm model is better at extracting an- swers when it is clearly stated in the text, but worse at guessing the answer in other cases. Overall, Shared-Normalization (S-Norm) achieved a score of 71.3 F1 on the TriviaQA web, a large improvement from the 56.7 F1 of the previous best system.
- On TriviaQA unfiltered dataset, results for our confidence methods show a more dramatic difference between these models. The shared-norm approach is the strongest, while the base model starts to lose performance as more paragraphs are used.
- On SQuAD dataset, the base model starts to drop in performance once more than two paragraphs are used. However, the shared-norm approach is able to reach a peak performance of 72.37 F1 and 64.08 EM given 15 paragraphs
Conclusion
When using a paragraph-level QA model across multiple paragraphs, the training method of sampling non-answer containing paragraphs while using a shared-norm objective function can be very beneficial. Combining this with suggested paragraph selection methods, using the summed training objective, and the proposed model design allows it to advance the state of the art on TriviaQA by a large stride